1 카프카 브로커
- 카프카 브로커는 카프카 클라이언트와 데이터를 주고 받기위해 사용되는 주체이자 데이터를 분산 저장하여 장애가 발생하더라도 안전하게 사용할 수 있도록 도와주는 애플리케이션이다.
- 하나의 서버에는 한 개의 카프카 브로커 프로세스가 실행된다.
- 카프카 브로커 서버 1대로도 기본 기능이 실행되지만 데이터를 안전하게 보관하기 위해 최소 3대 이상의 브로커를 1개의 클러스터로 묶어서 운영한다.
- 카프카 클러스터로 묶인 브로커들은 프로듀서가 보낸 데이터를 안전하게 분산 저장하고 복제하는 역할을 한다.
1.1 데이터 저장 전송
- 프로듀서로부터 데이터를 전달 받으면 카프카 브로커는 프로듀서가 요청한 토픽의 파티션에 데이터를 저장한다.
- 메모리가 아닌 파일 시스템에 데이터를 저장한다.
log.dir옵션에 지정한 디렉토리에 데이터를 저장한다.
- 컨슈머가 데이터를 요청하면 파티션에 저장된 데이터를 전달한다.
1.2 데이터 삭제
- 컨슈머가 데이터를 가져가더라도 토픽의 데이터는 삭제되지 않는다.
- 컨슈머나, 프로듀서가 데이터 삭제를 요청할 수 없다.
- 브로커만이 데이터를 삭제할 수 있다.
- 데이터 삭제는 로그 세그먼트라는 파일 단위로 이루어지며 이 세그먼트에는 다수의 데이터가 들어있어 특정 데이터를 선별해서 삭제할 수 없다.
- 세그먼트는 데이터가 쌓이는 동안 파일 시스템으로 열려있다.
log.segment.bytes또는log.segment.ms옵션 값에 따라 세그먼트 파일이 닫힌다.log.segment.bytes의 기본값은 1GB 해당 용량에 도달하면 세그먼트 파일이 닫힌다.- 닫힌 세그먼트 파일은
log.retention.bytes또는log.retention.ms옵션 설정값이 넘으면 삭제된다.
1.3 컨슈머 오프셋 저장
- 컨슈머 그룹은 토픽의 특정 파티션으로부터 데이터를 가져가서 처리하고 파티션의 어느 레코드까지 가져갔는지 확인을 위해 오프셋을 커밋한다.
- 커밋한 오프셋은
__consumser_offsets토픽에 저장된다. - 컨슈머 그룹은
__consumser_offsets토픽에 저장된 오프셋을 확인하고 다음 레코드를 가져가서 처리한다.
1.4 코디네이터
- 클러스터 중 한 대의 브로커가 코디네이터의 역할을 한다.
- 코디네이터는 컨슈머 그룹의 상태를 체크하고 파티션을 컨슈머와 매칭되도록 분배하는 역할을 한다.
- 컨슈머가 그룹에서 빠지면 매칭되지 않는 파티션을 정상 작동하는 컨슈머에게 할당한다.
- 이렇게 파티션을 컨슈머로 재할당하는 과정을 리밸런스(rebalance)라고 한다
1.4.1 Rebalancing
broker중하나가group coordinator역할을 한다.group coordinator는rebalancing을 발동시키는 역할을 한다.
컨슈머 그룹의 컨슈머에게 장애가 발생한다면
- 장애간 발생한
consumer에 할당된partition은 정상 작동하는consumer에 소유권이 넘어간다. - 이를
rebalancing이라 한다.
rebalancing은 두가지 상황에서 발생한다.
- 그룹에
consumer가 추가되는 상황 - 그룹에
consumer가 제외되는 상황
rebalancing 은 자주 일어나서��는 안 된다.
rebalancing이 발생 할 때consumer그룹의consumer들이topic의 데이터를 읽을 수 없기 때문
그룹에 consumer가 추가되는 상황 예시
- Library-events 토픽에 3개의 파티션이 존재함
- 아래 그림과 같이 컨슈머 인스턴가 하나인 경우 3개 파티션 모두가 하나에 컨슈머에 할당됨

- 잠시후 같은 그룹인 컨슈머 인스턴스 하나가 추가됨
rebalancing이 발생하여group coordinator가 파티션1을 새로운 인스턴스에 할당함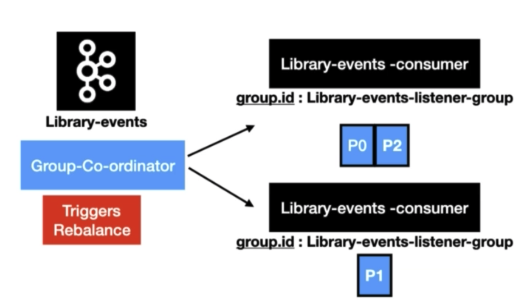
1.5 브로커 설정
필수 옵션
broker.id
- 카프카 브로커의 ID를 설정한다.
- id는 유일해야한다.
- 다른 브로커와 동일한 id를 가지면 비정상적인 동작이 발생할 수 있다.
zookeeper.connect
- 카프카 브로커와 연동할 주키퍼의 IP와 port를 설정한다.
log.dir
- 로그가 저장되는 위치
선택 옵션
listeners
- 카프카 브로커가 통신을 위해 열어둘 인터페이스 IP, port, 프로토콜을 설정한다.
- 설정하지 않으면 모든 IP와 port에서 접속할 수 있다.
advertised.listeners
- 카프카 클라이언트 또는 커맨드 라인 툴을 브로커와 연결할 때 사용하는 IP와 port 정보를 설정한다.
default.replication.factor
- 리플리케이션 팩터 옵션을 주지 않았을 경우 기본 값을 설정
- 2~3을 권장
min.insync.replicas
min.insync.replicas프로듀서가 메시지를 성공적으로 전송하기 위해 필요한 최소한의 동기화된 레플리카 수를 지정합니다- 프로듀서의
acks설정과 함꼐 쓰인다. - 손실 없는 데이터 전송을 원한다면
acks=all과min.insync.replicas=2토픽의 리플리케이션 팩터를 3으로 설정하는 것을 권장합니다.- 한 브로커의 장애를 허용하면서도 데이터 안정성을 유지할 수 있습니다.
- 2개의 레플리카만 ISR에 있지만, min.insync.replicas=2를 만족하므로 쓰기가 가능하고, acks=all은 이 2개의 ISR로부터만 확인을 받으면 됩니다.
auto.create.topics.enable
- 존재하지 않는 토픽을 퍼블리셔가 메세지를 보냈을 때 자동으로 토픽을 만드는 설정
- 프로덕션에선
auto.create.topics.enable=false
delete.topic.enable
- 토픽을 삭제 가능하게 설정
num.partition
- 파티션 개수를 명시하지 않고 토픽을 생성할 때 지정되는 파티션 개수를 설정한다.
offsets.retention.minutes
- 오프셋이 유지되는 시간을 설정한다
- 기본값 1일
- 독립적인 소비자의 경우 마지막 커밋 시간 후 이 보존 기간이 지나면 오프셋이 만료됩니다.
2 토픽(topic)
2.1 토픽의 개념
topic이란 카프카에서 데이터를 구분하기 위해 사용하는 단위이다.topic은 1개 이상의partition을 소유하고 있다.- 토픽을 생성할 때
partition수를 설정한다.
- 토픽을 생성할 때
3 파티션(partition)
3.1 파티션의 개념
partition이란topic을 분할한 것이며 이를 이용해 병렬처리를 제공한다.- 그룹으로 묶인
consumer들이record를 병렬로 처리함 consumer의 처리량이 한계치에 도달했다면consumer의 개수를 늘리고partition도 늘리면 처리량이 증가하는 효과를 볼 수 있다.partition에는producer가 보낸 데이터가 저장되어있다. 이 ��데이터를record라고 한다.record가 저장될 때partition내에서 순차적으로 증가하는 숫자를 부여받는데 이를offset이라 한다.offset은 순차적으로 증가하는 숫자 형태로 되어 있다.
3.2 적정 파티션 수
피티션 개수 고려사항
- 데이터 처리량
- 메세지 키 사용 여부
broker,consumer영향도
파티션은 카프카의 병렬처리의 핵심이다.
- 파티션의 개수가 늘리면 1:1 매핑되는 컨슈머 개수가 늘어난다.
데이터 처리 속도를 올리는 방법
- 컨슈머의 처리량을 올리는 것
- 스케일 업
- GC 튜닝
- 이 방식으로 일정 수준 이상의 처리량을 올리는 것이 어렵다.
- 파티션을 늘리고 컨슈머를 늘려 병렬 처리량을 올리는 것
적정 파티션 수
프로듀서 전송 데이터량 < 컨슈머 데이터 처리량 - 파티션 개수- 전체 컨슈머 데이터 처리량이 프로듀서가 보낸 데이터보다 작다면 컨슈머 랙이 생기고 데이터 처리 지연이 발생한다.
- 그렇기 때문에 컨슈머 전체 데이터 처리량이 프로듀서 데이터 처리량보다 많아야 한다.
파티션 수를 결정하는 팁
- 적절한 파티션 수를 측정하기 어려운 경우 일단 적은 수의 파티션으로 운영하고 병목현상이 생기면 파티션 수��와 프로듀서 또는 컨슈머를 늘려가는 방법으로 할당한다
- 카프카에선 파티션 수의 증가는 아무때나 가능하지만 줄이는 방법은 없기 때문
4 Replication
- 고가용성 분산 스트리밍 플랫폼인 카프카는 무수히 많은 데이터 파이프라인의 메인 허브 역할을 한다.
- 따라서 카프카는 초기 설계 단계에서 부터 일시적인 하드웨어 이슈 등으로 브로커 한두 대에서 장애가 발생하여도 안정적인 서비스롤 운영하도록 구상됐다.
- 즉 카프카는 Replication(데이터 복제)를 통해 카프카는 장애 허용 시스템으로 동작한다.
- 장애 허용 시스템 -> 클러스터로 묶인 브로커 중 일부에 장애가 발생해도 데이터가 유실되지 않는다.
4.1 Replication의 동작
- Replication 동작을 위해 토픽을 생성할 때 Replication factor라는 옵션을 필수적으로 지정한다.
- Replication factor 만큼의 데이터 복사복을 가지고 있어
Replication factor - 1개 까지의 브로커가 장애가 발생해도 메시지 손실 없이 안정적으로 메시지를 주고 받을 수 있다. - 카프카의 데이터 복제는 파티션 단위로 이루어진다.
- 복제된 파티션은 리더와 팔로워로 구성된다.
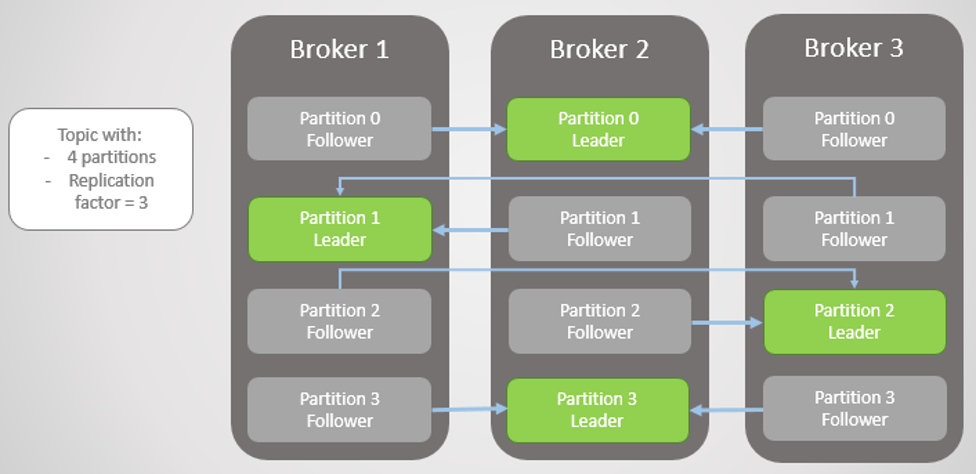
리더 파티션
- 프로듀서 또는 컨슈머와 직접 통신하는 파티션이다.
- 모든 읽기와 쓰기가 리더를 통해서만 일어난다.
- 프로듀서는 리더 파티션에만 쓰고 컨슈머는 리더 파티션만 읽는다.
- ISR이라는 그룹을 리더 파티션이 관리한다.
- 팔로워가 특정 주기의 시간만큼 복제 요청을 하지 않는다면 ISR 그룹에서 해당 팔로워를 추방한다.
- ISR은 밑에서 자세히 설명한다.
팔로워 파티션
- 복제 데이터를 가지고있는 파티션이다.
- 주기적으로 리더 파티션의 오프셋을 확인하여 자신의 오프셋과 차이가 있는 경우 리더로부터 데이터를 가져온다.
- 이 과정을 복제(replication)이라 한다.
- 리플리케이션의 동작 방식은 리더의 부담을 덜기 위해 팔로워가 리더를 풀하는 방식으로 동작한다.
리플리케이션 팩터
- 토픽 생성시 리플리케이션 팩터를 설정할 수 있는데 이는 파티션의 복제 개수를 의미한다.
- 토픽 별로 리플리케이션 팩터 값을 설정할 수 있다.
최소 1 ~ 최대 브로커의 개수만큼 설정 가능
- 클러스터 내 모든 브로커에 동일하게 설정해야한다.
- 리플리케이션 팩터의 값은 변경할 수 있다.
리플리케이션의 단점
- 리플리케이션으로 인해 다른 브로커에도 파티션의 데이터가 복제되므로 복제 개수만큼 저장 용량이 증가한다.
- 예) 토픽의 사이즈가 만약 100GB 이고 리플리케이션 팩터가 3인 경우 브로커 1에도 100GB의 디스크를 사용하고, 브로커2 에도 100GB 사용하고, 브로커3에더 100GB 사용해서 총 300GB로 원래 토픽 사이즈에 3배 크기의 저장소가 필요합니다.
- 리플리케이션을 보장하기 위한 작업으로 브로커의 리소스 사용량이 증가한다.
리플리케이션 팩터 결론
- 모든 토픽에 리플리케이션 팩터 3을 적용해서 운영하기 보다 토픽에 저장되는 데이터의 중요도에 따라 팩터를 달리 설정하는 것이 필요하다.
- 테스트나 개발 환경에서는 팩터 수를 1로 설정하자
- 로그성 메시지로 약간의 유실을 허용하는 운영환경 이라면 팩터 수를 2로 설정하자
- 유실을 허용하지 않는 운영 환경이라면 팩터 수를 3으로 설정하자
4.2 ISR(In Sync Replica)
- 리더 파티션이 다운되는 경우 팔로워 파티션이 새로운 리더로 승격할 때 데이터의 정합성을 지키기 위해 ISR이라는 개념을 도입했다.
- 리더 파티션과 팔로워 파티션은 ISR이라는 논리적 그룹으로 묶여있다.
- ISR에 속한 파티션만이 리더 파티션이 될 자격이 있다.
- 팔로워 파티션은 매우 짧은 주기로 리더 파티션의 새로운 메세지를 가져온다.
- 리더 파티션이 팔로워 파티션들이 주기적으로 데이터를 가져가고 있는지 확인해서 일정 주기(
replica.lag.time.max)동안 요청이 오지 않는다면 리더 파티션은 해당 팔로워 파티션을 ISR 그룹에서 추방한다.- 팔로워 파티션에 문제가 있어 리더 파티션으로 부터 데이터를 가져오지 못하면 데이터가 일치하지 않으�므로 해당 팔로워 파티션이 리더가 되면 데이터 손실이 발생하기 때문
- ISR 리스트 정보는 안전한 저장소인 주키퍼에 저장한다.
4.3 커밋
- 리더 파티션이 ISR 그룹을 관리한다.
- ISR 내에서 모든 팔로워 복제가 완료되면 리더는 내부적으로 커밋되었다는 표시를한다.
- 마지막 커밋 오프셋의 위치를 하이워터마크라고 한다.
- 즉 커밋되었다는 의미는 리플리케이션 팩터 수의 모든 리플리케이션이 전부 메시지를 저장했음을 뜻한다.
- 그리고 이렇게 커밋된 메시지만 컨슈머가 읽어갈 수 있다.
- 모든 브로커는 재시작될 때 커밋된 메시지를 유지하기 위해 로컬 디스크의 replication-offset-checkpoint라는 파일에 마지막 커밋 오프셋 위치를 저장한다.
- 해당 파일은 로그 디렉토리 경로에 저장된다.
4.4 레플리케이션 동작
- 모든 읽기와 쓰기가 리더를 통해서만 일어나기 때문에 리플리케이션을위해 팔로워들과 많은 통신을 한다면 결과적으로 리더의 성능이 떨어지게 된다.
- 카프카는 리더와 팔로워 간의 리플리케이션 동작에서 통신을 최소화해 리더의 부담을 줄였다.
동작
- 먼저
test-0이라는 파티션이 1개 존재하고 리플리케�이션 팩터가 3이라고 해보자. - 현재 리더 파티션이 0번 오프셋에 message1이라는 메시지를 가지고 있다.
- 프로듀서가 test라는 토픽으로 message1이라는 메시지를 전송하고 리더만 메시지를 저장하고 팔로워들은 메시지를 레플리케이션 하기 전 상태
- 팔로워들이 리더에게 0번 오프셋 메시지를 가져오기 위한 요청을 보냄
- 컨슈머는 주기적으로 리더 파티션에게 데이터를 요청함
- 받아온 메시지 message1을 리플리케이션 함
- 현 상태에서 리더는 모든 팔로워가 0번 오프셋 메시지를 레플리케이션하기 위한 요청을 보냈다는 것은 알고 있지만 성공적으로 복제했는지는 알 수 없다.(커밋을 할 수 없다.)
- 리더는 1번 오프셋에 새로운 메시지 message2를 받은뒤 저장한다.
- 팔로워들은 리더에게 1번 오프셋 메시지를 가져오기 위한 요청을 보냄
- 이 요청을 모든 팔로워한테 받은 리더는 1번을 달라고 하는 것을 보니 0번은 이미 성공적으로 저장했구나라고 인식하고 오프셋 0에 대해 커밋 표시를 하고 하이워터마크를 증가시킨다.
- 0번 오프셋에 대해서 레플리케이션을 성공하지 못했다면 팔로워는 1번이 아니라 0번 오프셋에 대한 요청을 다시 보냈을 것이다.
- 즉 리더는 팔로워 들이 보내는 레플리케이션 요청의 오프셋을 보고 팔로워들이 어느 위치의 오프셋까지 레플리케이션을 성공했는지 알 수 있다.
- 팔로워가
N번 오프셋을 요청하면N-1번 오프셋의 레플리케이션이 성공했다는 것이다.
- 리더는 응답으로 0번 오프셋 message1이 메시지가 커밋되었다고 전달한다.
- 이 응답을 받은 팔로워들은 0번 오프셋 메시지가 ��커밋되었다는 사실을 인지하고 리더와 동일하게 커밋을 표시한다.
- 반복
특징
- 카프카에서 리더와 팔로워들의 레플리케이션 동작 방식은 리더가 푸시하는 방식이 아니다.
- 팔로워가 풀하는 방식으로 동작하는데 이는 리더의 부하를 줄이기 위함이다.
5 컨트롤러
- 클러스터 중 한 대의 브로커가 컨트롤러 역할을 한다.
- 컨트롤러는 다른 브로커들의 상태를 체크하고 브로커가 클러스터에서 빠지는 경우 해당 브로커에 존재하는 리더 파티션을 재분배한다.
- 컨트롤러 역할을 하는 브로커가 장애가 생기면 다른 브로커가 컨트롤러 역할을 한다.
- 컨트롤러는 리더 파티션을 선출하기 위해 안전한 주키퍼에 저장되어 있는 ISR 리스트를 사용한다.
- 만약 브로커의 실패가 감지되면 즉시 ISR 리스트 중 하나를 새로운 파티션 리더로 선출한다.
- 그리고 새로운 리더의 정보를 주키퍼에 기록하고 변경된 정보를 모든 브로커에 전달한다.
5.1 리더 선출 과정
- 파티션 0번의 리더가 있는 브로커 1번이 예기치 않게 다운된다.
- 브로커 1번과 연결이 끊어진 주키퍼는 0번 파티션의 ISR에서 변화를 감지한다.
- 컨트롤러가 주키퍼 워치를 통해 0번 파티션의 변화를 감지하고 해당 파티션 ISR ��중 3번을 새로운 리더로 선출한다.
- 컨트롤러가 0번 파티션의 리더가 3이라는 정보를 주키퍼에 기록한다.
- 갱신된 정보가 활성화된 모든 브로커에 전파된다.
6 레코드(record)
레코드
record는 타임스탬프, 메시지 키, 메시지 값, 오프셋으로 구성되어 있다.broker에 한번 적재된record는 수정할 수 없고 로그 리텐션 기간 또는 용량에 따라서만 삭제된다.
메시지 키
- 메시지 키는 메시지 값을 순서대로 처리하거나 메시지 값의 종류를 나타내기 위해 사용된다.
producer가topic에record를 전송할 때 메시지 키의 해시값을 토대로partition을 지정한다.- 즉 동일한 메시지 값이라면 동일한
partition에 들어간다.
- 즉 동일한 메시지 값이라면 동일한
- 메시지 키를 사용하지 않으면 레코드는 프로듀서 기본 설정 파티셔너에 따라
partition에 분배되어 적재된다.
메시지 값
- 실질적으로 처리할 데이터가 들어가 있다.
- 메시지 키와 메시지 값은 직렬화되어 브로커로 전송되기 때문에 컨슈머가 동일한 형태로 역직렬화를 수행해야한다.
타임스탬프
producer가 생성한record가broker로 전송되면 타임스탬프가 지정되어 저장된다.- 타임스탬프는
broker기준 유닉스 시간이 설정된다. - 프로듀서가 레코드를 �생성할 때 임의의 타임스탬프 값을 설정할 수 있다.
오프셋
producer가 생성한record가broker로 전송되면 오프셋이 지정되어 저장된다.record의 오프셋은 0이상의 숫자이며partition내에서 유일하다.record의 오프셋은 직접 지정할 수 없고 브로커에 저장될 때이전 전송된 레코드 오프셋 + 1값이 설정된다.- 즉 아래의 그림과 같이 0부터 시작하여 순차적으로 증가한다.
- 오프셋은
consumer가 데이터를 가져갈 때 사용한다.- 오프셋을 이용해 그룹으로 이루어진 컨슈머들이 파티션의 데이터를 어디까지 가져갔는지 알 수 있다.
- 오프셋을 이용해 파티션 내에서 메세지의 순서를 보장합니다.
- 허나 서로 다른 파티션의 동일한 값의 오프셋끼리의 순서는 보장하지 않는다.
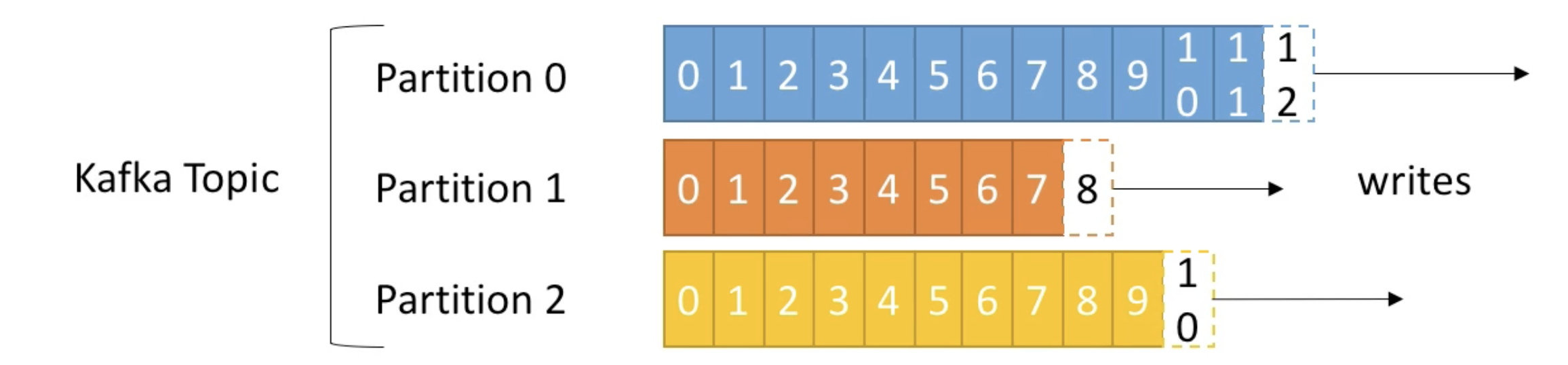
7 세그먼트(segment)
- 프로듀서가 카프카로 전송한 메시지는 토픽 내 각 파티션의 로그 세그먼트에 저장된다.
- 브로커의 설정에서
log.dirs으로 지정한 디렉토리에 파티션이 저장된다. - 만약 토픽 이름이
topic_name이라면log.dirs로 지정된 디렉토리에topic_name-0이라는 디렉토리가 생��긴다. 토픽 이름 뒤에 붙은0이라는 숫자는 파티션 번호를 나타낸다. topic_name-0디렉토리의 리스트를 확인하면 아래와 같은 파일이 있다..index: 로그 세그먼트에 저장된 위치와 오프셋 정보를 기록하는 파일.log: 실제 메시지들이 저장되는 파일.timeindex: 메지시의 타임스탬프를 기록하는 파일
- 브로커의 설정에서
- 각 메시지(레코드)들은 세그먼트라는
로그 파일의 형태로 브로커의 로컬 디스크에 저장됩니다. - 로그 세그먼트에는 메시지의 내용만 들어가는 것이 아니라 메시지의 키, 밸류, 오프셋, 메시지 크기와 같은 정보가 함꼐 저장된다.
- 하나의 로그 세그먼트가 너무 크면 관리가 어렵기 때문에 세그먼트의 크기는 최대 1GB가 기본값으로 설정되어 있다.
- 따라서 카프카로 들어오는 메시지를 계속해서 세그먼트에 덧붙이다가 최대 크기에 도달하면 해당 세그먼트 파일을 클로즈하고 새로운 세그먼트를 생성하는 방식으로 진행된다.
- 브로커 세그먼트에 저장된 메시지는 컨슈머가 읽어갈 수 있다.
7.1 세그먼트 관리
- 로그 세그먼트가 무한히 늘어날 경우를 대비해 로그 세그먼트에 대한 관리 계획이 필요하다
- 로그 세그먼트를 관리하는 방법은 크게 로그 세그먼트 삭제와 컴팩션이다.
7.2 세그먼트 삭제
- 로그 세그먼트 삭제 옵션은 브로커 설정에서
log.cleanup.policy를delete로 설정해야 한다. log.cleanup.policy의 기본값이delete이기 떄문에 옵션을 따로 설정하지 않으면 삭제 정책이 적용된다.- 토픽의
log.retention.ms옵션으로 로그 세그먼트 보관 시간을 설정할 수 있다.- 레퍼런스
- 토픽마다 보관 주기를 관리할 수 있다.
- 로그 세그먼트 보관 시간이 해당 숫자보다 크면 세그먼트를 삭제한다.
- 토픽에 별다른
log.retention.ms를 설정하지 않으면 카프카의 server.properties에 적용된 옵션값이 적용된다. - 카프카의 기본 설정값은 7일로 모든 세그먼트 파일은 7일이 지나면 전부 삭제된다.
log.retention.bytes옵션으로 크기를 기준으로 로그 세그먼트를 관리할 수도 있다.- 로그 세그먼트 작업은 일정 주기를 가지고 체크한다.
- 카프카 기본 값은 5분이다.
- 5분 간격으로 로그 세그먼트 파일을 체크하면서 삭제 작업을 진행한다.
7.3 로그세그먼트 컴팩션
- 컴팩션 정책은 로그 세그먼트를 삭제하지 않고 컴팩션해서 보관한다.
- 로그 컴팩션은 현재 활성화된 세그먼트를 제외하고 나머지 세그먼트를 대상으로 컴팩션이 진행된다
참고