Logging-Architecture
1 Logging Architecture
-
컨테이너 엔진 또는 런타임에서 제공하는 기본 기능으로는 전체 로깅 솔루션을 사용하기에 충분하지 않다.
-
컨테이너가 crash 되거나 파드가 퇴출거나 노드가 죽어도 로그를 보길 원하기 때문에 클러스터에서 로그는 노드, 포드 또는 컨테이너와 독립적으로 별도의 스토리지 및 라이프 사이클을 가져야 한다.
- 이러한 컨셉을
cluster-level logging이라고 한다.
- 이러한 컨셉을
-
cluster-level logging 아키텍처는 분리된 백엔드가 필요하다.
- 이 분리된 백엔드에 로그 저장, 분석, 조회 기능이 있다.
-
쿠버네티스는 자체적으로 cluster-level logging 솔루션을 제공하지 않는다.
- 하지만 다양한 솔루션을 쿠버네티스에 적용할 수 있다.
2 Pod and container logs
- 쿠버네티스는 파드에서 동작 중인 각각의 컨테이너로부터 로그를 캡쳐한다.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args: [ /bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done' ]
- 위 예제는 1초 마다 standard output stream으로 ��텍스트를 쓰는 pod이다.
$ kubectl logs counter
0: Fri Apr 1 11:42:23 UTC 2022
1: Fri Apr 1 11:42:24 UTC 2022
2: Fri Apr 1 11:42:25 UTC 2022
- 쿠버네티스가 캡쳐한 로그는 kubectl logs 명령어로 볼 수 있다.
2.1 How nodes handle container logs
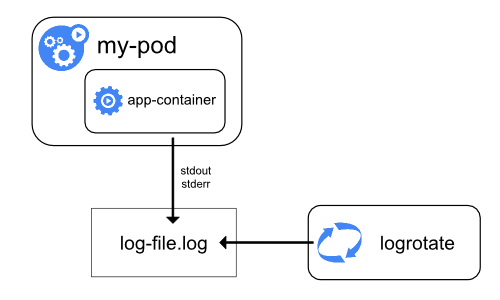
-
컨테이너 런타임은 컨테이너에서 만들어지는
stdoutandstderrstreams을 처리하고 리다이렉트 한다.- 컨테이너 런타임마다 로그를 처리하는 방식이 다르다.
-
Kubelet은 기본적으로 컨테이너를 다시 시작하면 종료된 컨테이너 하나를 로그와 함께 보관한다.
-
노드에서 파드를 제거하면 포함된 모든 컨테이너와 로그가 함께 제거된다.
-
Kubelet은 Kubernetes API의 기능을 통해 클라이언트가 로그를 사용할 수 있도록 한다.
kubectl logs
-
컨테이너의 로그는 컨테이너 런타임 마다 로그의 저장 위치가 다르지만 CRI 프로토콜에 따라
/var/log/pods/<PodUID>/<container-name>/0.log로 접근할 수 있다.
2.2 Log Rotaion
- 레퍼런스
- 로그 파일에 로그 엔트리가 계속해서 쌓이게 되는데 이를 관리하는 방법을 알아보자.
- kubelet의 Log Rotaion 설정을 통해 로그 파일을 자동으로 관리할 수 있다.
- kubelet이 CRI를 통해 컨테이너 런타임에게 명령을 전달하면 컨테이너 런타임이 주어진 위치에 컨테이너 로그를 기록하는 방식이다.
- kubelet의
containerLogMaxSize,containerLogMaxFiles설정해서 로그 파일을 관리한다.containerLogMaxSize: 로그 파일 하나의 최대 크기containerLogMaxFiles: 컨테이너 하나가 가질 수 있는 최대 로그 파일의 개수
2.3 Log Location
- kubelet과 container runtime이 로그를 작성하는 방식은 노드의 OS의 영향을 받는다.
- systemd를 사용하는 Linux 노드의 경우 kubelet and container runtime은 기본적으로 journald에 로그를 쓴다.
journalctl -u kubelet명령어로 로그를 확인할 수 있다.- systemd가 존재하지 않는 경우 로그 파일을
/var/log디렉토리에 작성한다.
3 Cluster-level logging architectures
- 3가지 방식으로 아키텍처를 구성할 수 있다.
- 모든 노드에 logging agent를 놓는 방식
- logging을 위한 사이드카 컨테이너를 pod에 포함시키는 방식
- 애플리케이션에서 logging backend로 직접 로그를 전송하는 방식
3.1 Using a node logging agent
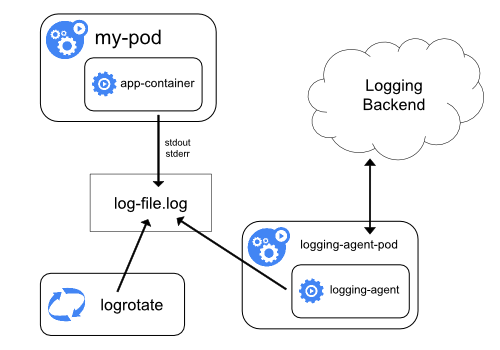
- logging agent를 각각의 노드에 하나씩 배치시키는 방법이다.
- logging agent가 로그를 logging backend로 보내는 역할을 한다.
- 일반적으로 logging agent는 해당 노드에서 작동하는 모든 컨테이너의 로그 파일에 직접 접근이 가능하다.
- 노드 당 하나의 logging agent가 필요하기 때문에
DaemonSet을 이용해 agent를 배포하는 것이 좋다. - Containers가 생성하는 로그의 포맷은 통일성이 없기 때문에 logging agent이를 파싱해서 logging backend 기능이 추가적으로 필요할 수 있다.
3.2 Sidecar container with a logging agent
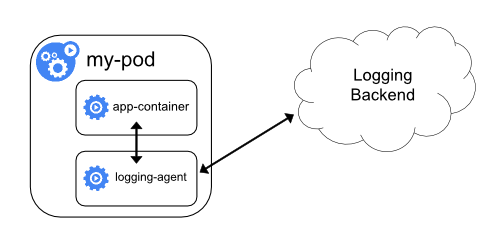
- 만약 노드 레벨의 logging agent가 적합하지 않은 상황이라면 파드에 사이드카로 logging agent를 추가할 수 있다.
- logging agent를 사이드카로 사용하는 것은 엄청난 양의 리소스를 소비할 수 있으니 주의하자.
3.3 Exposing logs directly from the application
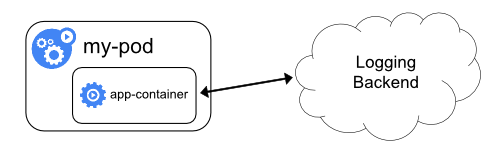
- 애플리케이션 컨테이너가 직접 logging backend로 로그를 전달하는 방식